
Executive summary
In the agentic era, educational publishers and academic institutions face an existential paradox. Large Language Models (LLMs) and autonomous AI agents have become the default interface for students, researchers, and educators globally.
For intellectual property (IP) holders, traditional options present a false dichotomy: block AI bots and risk immediate digital obsolescence or allow them to scrape your data and watch decades of proprietary pedagogical frameworks dissolve into open-source training weights.
This leaves media executives with a high-stakes dilemma:
- If you block AI scrapers entirely via robots.txt and firewalls, your content becomes invisible to the next generation of learners.
- If you sign traditional, flat-fee data-licensing agreements, you effectively hand over the “crown jewels.” You allow foundation models to absorb your proprietary expertise, strip away your brand permanence, and build competing educational ecosystems on top of your own data.
Static licensing models are a depreciating asset. The future demands a fundamental shift from static data delivery to real-time context streaming.
By leveraging the Model Context Protocol (MCP), publishers can transition from being vulnerable targets of AI data ingestion to becoming the secure, sovereign, and monetized knowledge infrastructure powering the AI ecosystem.
The threat: Why static scraping is a losing game for publishers
To understand why a new protocol is necessary, we must look closely at the hidden vulnerabilities of current AI data agreements and scraping realities:
The erosion of value through model absorption: When an LLM ingests a textbook during pre-training or fine-tuning, the data is essentially commoditized. The model learns the underlying concepts and can replicate them without ever referencing the publisher’s core platform or requiring a user license.
This industrial-scale data-ingestion treats copyrighted educational catalogs as freely available raw material, bypassing legitimate revenue models and threatening institutional survival. This market friction reached a flashpoint on May 5, 2026, when a coalition of major academic and trade publishers led by Elsevier filed a landmark copyright complaint against tech giants in the Southern District of New York (Elsevier Inc. v. Meta Platforms, Inc.) [^1]. The litigation underscores a critical structural vulnerability: traditional licensing models result in irreversible value leakage, stripping data provenance the moment content is absorbed into public parametric memory.
The decay of content currency and accuracy: Educational content is a living asset. Medical manuals update clinical guidelines; tax codes change annually; scientific discoveries rewrite chapters. Static datasets decay the moment they are exported. When an AI outputs outdated information extracted from a stale dataset, the student receives a subpar education, and the publisher suffers reputational damage. In the agentic economy, real-time context currency is a prerequisite for brand authority.
The loss of provenance and brand dilution: Traditional digital rights management (DRM) breaks down entirely within an LLM framework. In a conversational interface, the student or researcher rarely knows if an answer was derived from a peer-reviewed, authoritative text or an unverified blog post. Without direct attribution, verifiable context delivery, and clear user routing, the brand value of the publisher vanishes into the chat interface.
The total failure of legacy technical defenses
Publishers attempting to protect their assets using legacy perimeter defenses find themselves fundamentally unequipped to handle autonomous agent discovery. Traditional gatekeeping protocols fail for specific technical reasons:
- Robots.txt modifications: These files operate on an honor system. Sophisticated, multi-hop LLM crawlers and multi-agent discovery bots routinely ignore or circumvent them to scrape deep web architectures.
- Standard paywalls and rate-limiting: While effective at stopping casual human scraping, these mechanisms block the very structural visibility required for legitimate AI systems to discover and reference premium content, effectively rendering the publisher invisible in the agentic era.
- Static API endpoints: Exposing raw text via standard REST APIs allows LLMs to programmatically reconstruct entire corpuses over time through distributed query patterns, leading to rapid content devaluation.
When core pedagogical frameworks are reduced to static vectors in public foundational models, publishers suffer a critical triple blow: the systematic erosion of recurring subscription revenue, a total loss of content integrity, and the dangerous propagation of unverified hallucinations served to the public under the guise of their own trusted brand.
Enter the Model Context Protocol (MCP)
The Model Context Protocol (MCP) is not just an open-source technical standard; it is a profound business model enabler. Co-developed by industry pioneers and rapidly becoming the universal data-connectivity standard, MCP acts as a secure, real-time gateway—a universal adapter—between a publisher’s secure databases and any frontier AI client (such as Claude, OpenAI Assistants, or enterprise university portals).
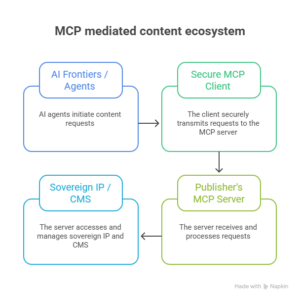
Instead of sending your raw content out to the AI, MCP allows the AI to securely pull context in on an as-needed basis. This operates on a Zero-Knowledge, Just-In-Time architecture:
- The Request: A student asks an AI-powered tutor to explain a complex organic chemistry process or critique a specific case study.
- The Handshake: Rather than hallucinating or relying on scraped web data, the AI client reaches out to the publisher’s dedicated, secure MCP server.
- The Stream: The MCP server surfaces only the exact text snippet, diagram, or dataset required to ground that specific prompt.
- The Resolution: The AI delivers a precise, fully cited answer to the user. Once the session terminates, the proprietary data vanishes from the AI model’s active context window.
The baseline implication: The core textbook, test bank, or media asset is never ingested, never stored, and never used to train the base model. Your IP stays behind your secure perimeter.
Paradigm shift: Comparing static scraping vs. protocol-driven engagement
To maximize visibility across discovery platforms like Google AI Overviews and enterprise search engines, technology leaders must evaluate data infrastructure through a protocol-driven lens. The following framework outlines the operational shifts required to move from vulnerable ingestion to proactive context streaming:
| Operational Metric | Traditional vector ingestion model | MCP-enabled context server model |
| Data ownership and control | Relinquished upon ingestion; data becomes a permanent vector in external systems. | Absolute; data stays within enterprise boundaries; access is granted per query. |
| Context freshness and latency | High latency; model data is static until the next training or retrieval-augmented generation (RAG) update cycle. | Zero latency; real-time database queries ensure agents always serve the latest editions and corrections. |
| Revenue and monetization | Flat, single-instance licensing fees or completely unmonetized through unauthorized scraping. | Highly scalable; utility-based billing driven by per-query or tiered contextual monetization. |
| Security and resilience | Vulnerable to prompt injection attacks that can leak large chunks of copyrighted underlying data. | High resilience; hardened gateways and explicit server schemas isolate backend logic from direct LLM manipulation. |
The business case: From flat licensing to metered content economies
Transitioning from an open repository to a structured AI integration services architecture unlocks modern, recurring economic models for educational publishers.
Per-query monetization
By wrapping premium assets inside an MCP server, content delivery transforms into a highly predictable utility model akin to cloud computing. Publishers can implement micro-metering infrastructure to track every individual context call, charging LLM providers, corporate learning platforms, or university networks fractionally per query.
Dynamic content control
In a static environment, correcting an outdated scientific formula or modifying a legal curriculum requires an expensive, multi-month distribution lifecycle. With an MCP server built on an agile data modernization framework, any backend update instantly populates across every global AI agent querying the endpoint. Real-time accuracy becomes a premium product tier that platforms are willing to pay for.
Granular access tiers
Publishers do not need to lock away their entire catalog to protect it. MCP allows for highly sophisticated content segmentation:
- Public Tier: Foundational glossary terms, basic definitions, and citations are made openly discoverable to maximize indexing on AI discovery search engines.
- Premium Tier: Advanced problem-solving logic, interactive case studies, and proprietary QTI test banks are gated behind secure cryptographic tokens, accessible only to authorized LLM applications.
The blueprint: A three-phase roadmap for EdTech executives
Implementing an enterprise-ready MCP architecture requires a meticulous convergence of data modernization, protocol engineering, and strict API runtime management.
Phase 1: Asset auditing and structuring
Before deploying an external-facing gateway, legacy data stores must be standardized. Publishers must conduct a comprehensive inventory of unstructured formats (such as EPUBs, locked PDFs, and legacy content management systems) and convert them into highly queryable semantic repositories. This phase leverages structured taxonomy tagging to ensure that data fields map cleanly to the resource schemas expected by the MCP standard.
Phase 2: Building the secure MCP layer
The core engineering task involves wrapping the modernized repository inside a secure, hardened MCP server. Operating through the lens of a CTO, this requires building an architecture that natively supports JSON-RPC communication protocols while layering enterprise control planes over the server instance. Technology teams must deploy robust authentication mechanisms, advanced token validation, rate-limiting rules, and automated input-output screening to prevent malicious prompt injections from executing arbitrary backend commands.
Phase 3: Ecosystem interoperability
The final phase focuses on exposing the secure MCP endpoints to accredited AI hosts and client applications. By providing clean, discoverable developer documentation and standardized schemas to verified LLM providers, school districts, and institutional networks, publishers establish their databases as the premier, authoritative nodes for educational context.
Own the context, own the future
The educational publishers and academic institutions that thrive in the agentic era will not be those that build the tallest firewalls to isolate themselves from modern technology, but those that design the smartest, most secure pipelines.
This is where specialized engineering execution becomes a critical differentiator. Educational institutions excel at creating world-class, transformative pedagogical content; they should not have to divert core resources to become specialized AI protocol and network engineers.
As an industry leader in enterprise AI deployments, Clavis Tech serves as the strategic engineering partner for premier publishers navigating this transition. Through our comprehensive custom AI engineering capabilities, we design, deploy, and maintain the secure, metered MCP server environments required to safeguard your intellectual property. By aligning your premium content with state-of-the-art context streaming protocols, we ensure your data remains verified, resilient against exploitation, and highly profitable in an AI-first economy.